使用物化视图
ClickHouse 支持两种类型的物化视图:增量 和 刷新。虽然这两者都是通过预计算和存储结果来加速查询,但它们在底层查询的执行方式、何时执行、适合的工作负载以及数据新鲜度管理方面存在显著差异。
用户应该考虑针对特定的查询模式使用物化视图,这些模式需要加速,前提是已经执行了有关类型的最佳实践 regarding type 和 主键优化。
增量物化视图 实时更新。当新数据插入到源表时,ClickHouse 会自动将物化视图的查询应用于新的数据块,并将结果写入到单独的目标表中。随着时间的推移,ClickHouse 将这些部分结果合并以生成一个完整的、最新的视图。这种方法非常高效,因为它将计算成本转移到插入时,仅处理新数据。因此,对目标表的 SELECT 查询执行快速且轻量。增量视图支持所有聚合函数,并且可以很好地扩展——甚至达到宠物字节级别的数据——因为每个查询操作于正在插入的数据集的一个小而近期的子集上。

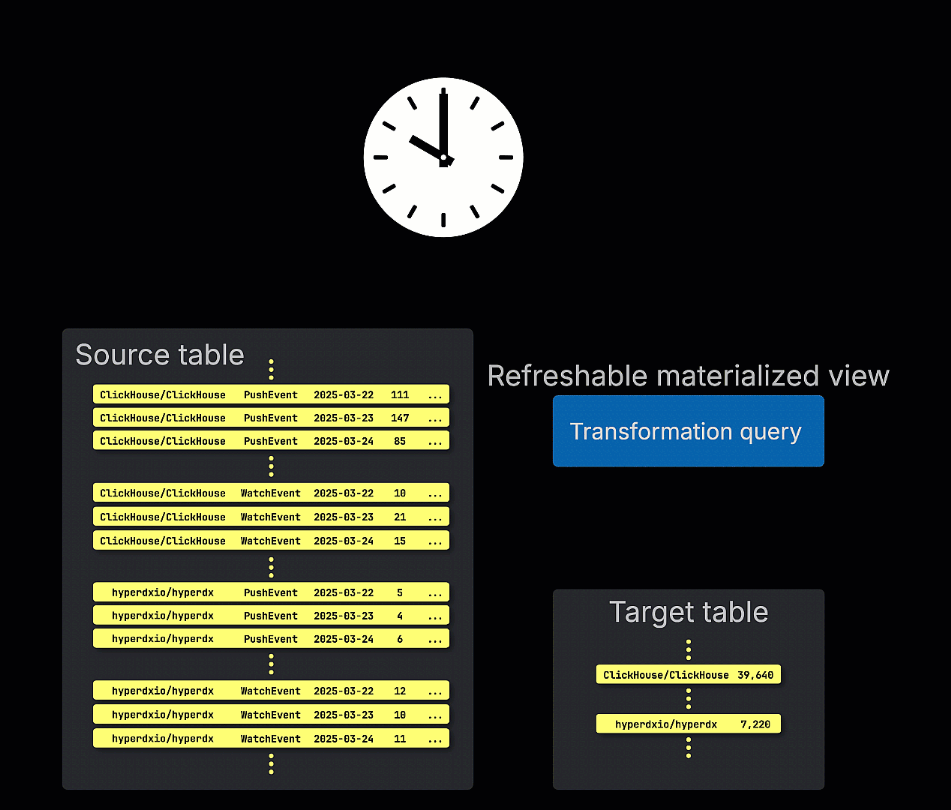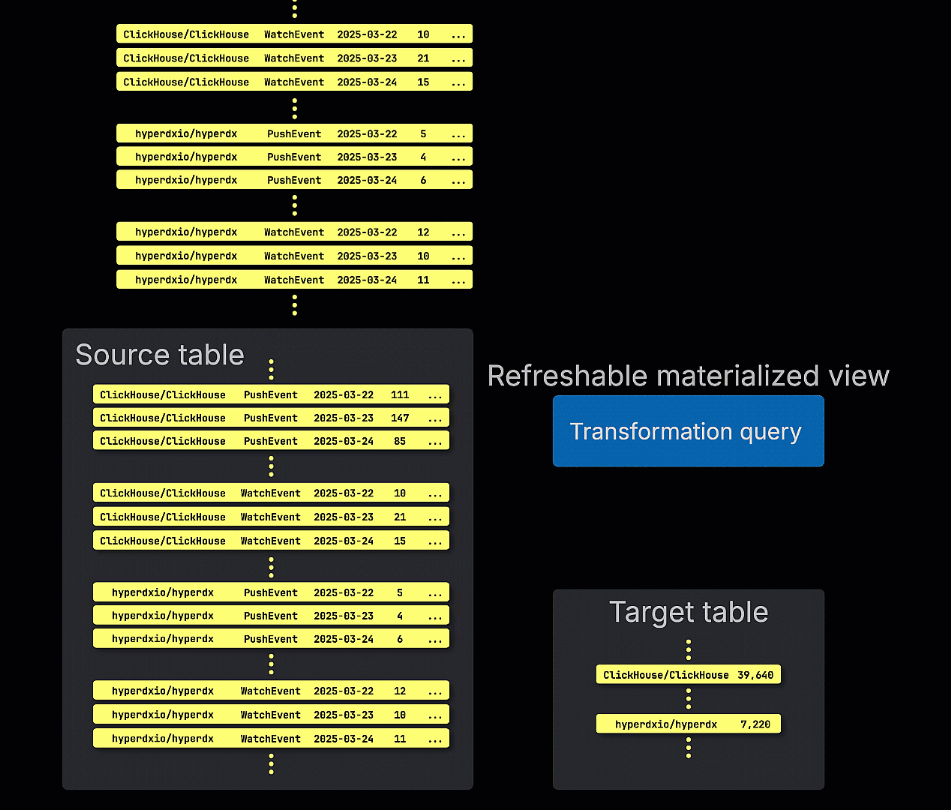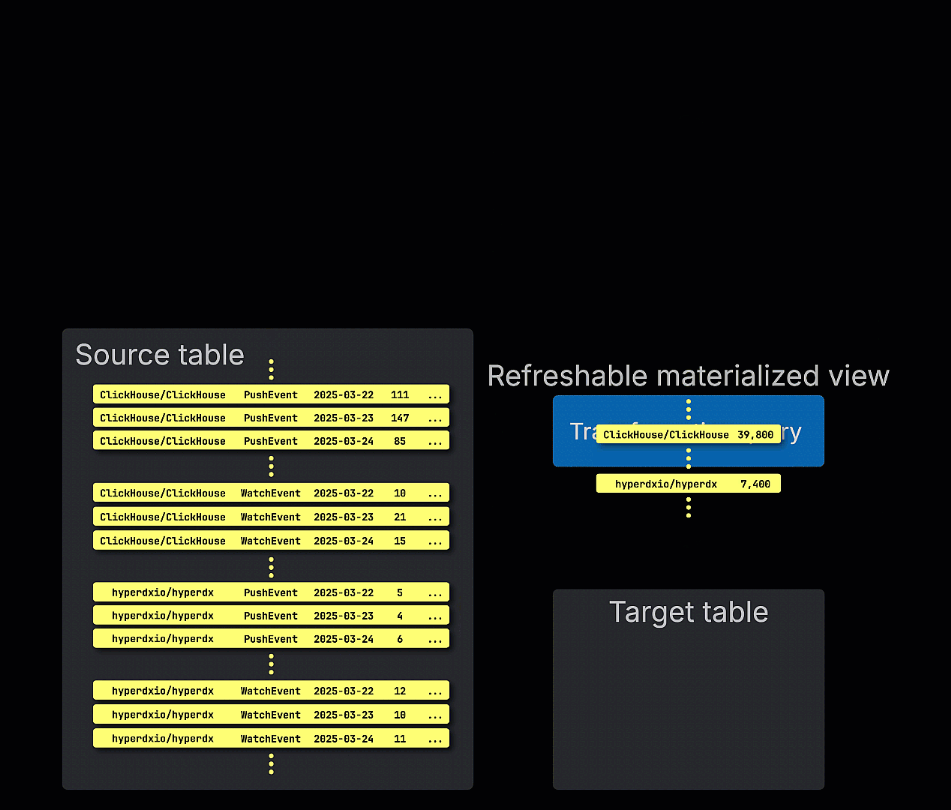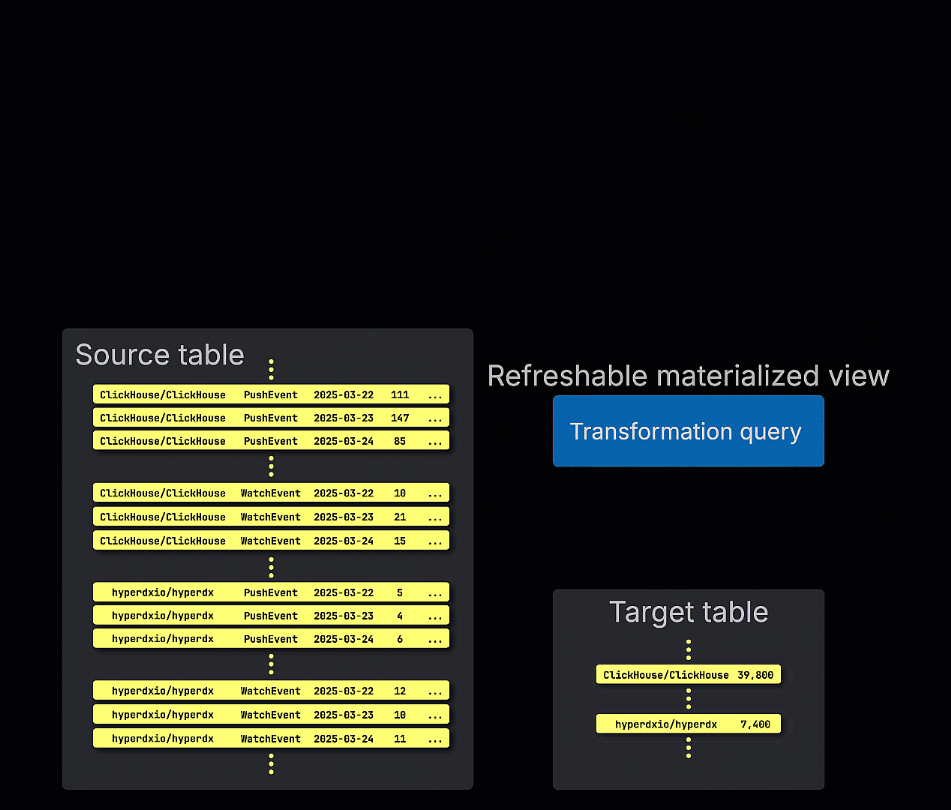
刷新物化视图,相对而言,按计划更新。这些视图定期重新执行它们的完整查询,并在目标表中覆盖结果。这类似于传统 OLTP 数据库(如 Postgres)中的物化视图。
在增量和刷新物化视图之间的选择在很大程度上取决于查询的性质、数据变更的频率,以及是否必须在每次插入时反映更新,或者是否可以接受定期刷新。理解这些权衡对于在 ClickHouse 中设计高效、可扩展的物化视图至关重要。
何时使用增量物化视图
增量物化视图通常是首选,因为它们在源表接收新数据时会自动实时更新。它们支持所有聚合函数,特别适用于对单个表的聚合。通过在插入时增量计算结果,查询运行在显著较小的数据子集上,使这些视图能够轻松扩展到宠物字节级别的数据。在大多数情况下,它们对整体集群性能不会产生显著影响。
使用增量物化视图的情况:
- 您需要每次插入时更新的实时查询结果。
- 您需要频繁聚合或过滤大量数据。
- 您的查询涉及对单个表的简单转换或聚合。
有关增量物化视图的示例,请参见 此处。
何时使用刷新物化视图
刷新物化视图按周期性执行其查询,而不是增量执行,存储查询结果集以便快速检索。
它们在查询性能至关重要(例如,亚毫秒延迟)且可以接受稍微过时的结果时最有用。由于查询会被完全重新运行,刷新视图最适合于相对快速计算或可以在不频繁的间隔(例如每小时)计算的查询,例如缓存“前 N”结果或查找表。
执行频率应仔细调整,以避免对系统造成过大负载。极为复杂且消耗大量资源的查询应谨慎安排——这些会通过影响缓存并消耗 CPU 和内存而导致整体集群性能下降。查询的运行时间应相对较快,以避免超负荷集群。例如,如果查询本身需要至少 10 秒钟才能计算,则不应每 10 秒更新一次视图。
摘要
总结一下,使用刷新物化视图的情况:
- 您需要立即可用的缓存查询结果,并且小的延迟在新鲜度上是可以接受的。
- 您需要查询结果集的前 N。
- 结果集的大小不会随着时间的推移而无限增长。这将导致目标视图的性能下降。
- 您正在执行复杂的连接或涉及多个表的非规范化操作,需要在任何源表更改时进行更新。
- 您正在构建批处理工作流、非规范化任务或创建类似于 DBT DAG 的视图依赖关系。
有关刷新物化视图的示例,请参见 此处。
APPEND 与 REPLACE 模式
刷新物化视图支持两种模式来写入目标表数据:APPEND 和 REPLACE。这些模式定义了在刷新视图时,如何写入视图查询的结果。
REPLACE 是默认行为。每次刷新视图时,目标表的先前内容会完全被最新的查询结果覆盖。这适合于视图应始终反映最新状态的用例,例如缓存结果集。
相对而言,APPEND 允许将新行添加到目标表的末尾,而不是替换其内容。这使得其他用例,例如捕获定期快照成为可能。当每次刷新代表一个特定的时间点或需要历史结果积累时,APPEND 特别有用。
选择 APPEND 模式的情况:
- 您希望保留过去刷新记录。
- 您正在构建定期快照或报告。
- 您需要随时间逐步收集刷新结果。
选择 REPLACE 模式的情况:
- 您只需要最新的结果。
- 应完全丢弃过时的数据。
- 该视图代表当前状态或查找。
用户可以在构建 Medallion 架构 时找到 APPEND 功能的应用实例。
