选择分区键
分区主要是一种数据管理技术,而不是查询优化工具,尽管它可以在特定工作负载中提升性能,但不应作为加速查询的第一机制;分区键必须谨慎选择,清楚其影响,仅在符合数据生命周期需求或良好理解的访问模式时应用。
在 ClickHouse 中,分区将数据按照指定的键组织成逻辑段。这是在创建表时使用 PARTITION BY 子句定义的,通常用于按时间间隔、类别或其他业务相关维度对行进行分组。每个分区表达式的唯一值在磁盘上形成自己的物理分区,ClickHouse 为这些值中的每一个存储数据于单独的部分。分区改善了数据管理,简化了保留策略,并能帮助处理某些查询模式。
例如,考虑以下带有分区键 toStartOfMonth(date) 的英国价格支付数据集表。
每当一组行插入到表中时,ClickHouse 不会创建一个单一的数据部分来包含所有插入的行(如 这里 所述),而是为每个插入行中的唯一分区键值创建一个新数据部分:

ClickHouse 服务器首先根据其分区键值 toStartOfMonth(date) 将上面示例插入中由 4 行组成的行分割开。然后,对于每个识别的分区,这些行像往常一样 处理,执行几个顺序步骤(① 排序,② 划分列,③ 压缩,④ 写入磁盘)。
要获取关于分区的更详细解释,我们推荐本指南。
启用分区后,ClickHouse 仅在分区内合并 数据部分,而不是跨分区。我们为上面的示例表进行概述:
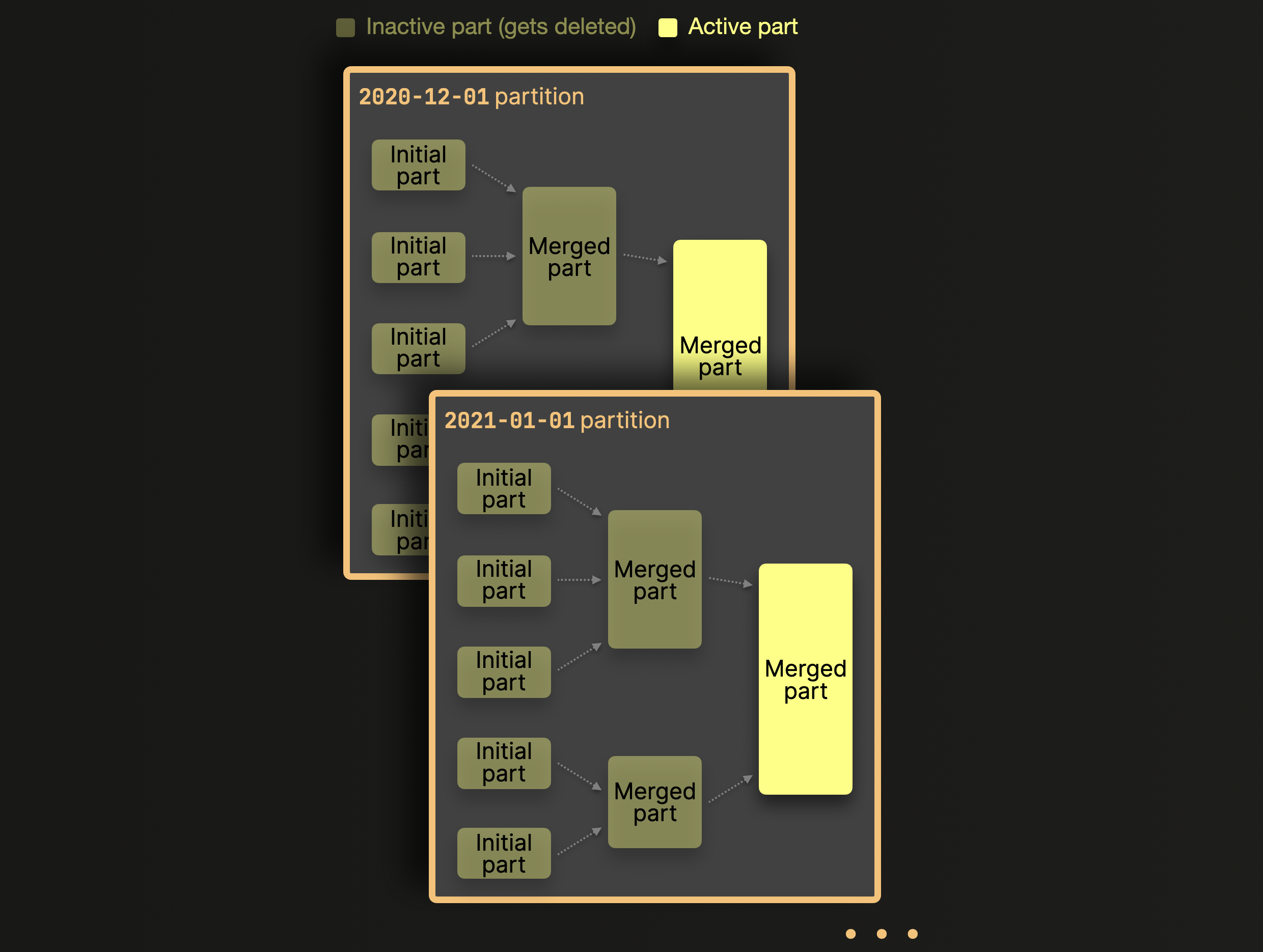
分区的应用
分区是管理 ClickHouse 中大数据集的强大工具,尤其在可观察性和分析用例中。它通过允许与时间或业务逻辑对齐的整个分区一次性删除、移动或归档,来实现有效的数据生命周期操作。这比逐行删除或复制操作要快得多且资源消耗更少。分区还与 ClickHouse 功能如 TTL 和分层存储无缝集成,使得在无需自定义协调的情况下实施保留策略或热/冷存储策略成为可能。例如,可以将最近的数据保留在快速的 SSD 储存上,而将较老的分区自动转移到更便宜的对象存储中。
虽然分区可以提升某些工作负载的查询性能,但也可能对响应时间产生负面影响。
如果分区键不在主键中并您按其过滤,则用户可能会看到分区提升查询性能。有关示例,请参见此处。
相反,如果查询需要跨分区查询,性能可能会由于总部分数的增加而受到负面影响。因此,用户在考虑将分区作为查询优化技术之前,应该了解其访问模式。
总之,用户应将分区主要视为一种数据管理技术。有关管理数据的示例,请查看来自可观察性用例指南的 "管理数据" 和来自核心概念 - 表分区的 "表分区的用途是什么?"。
选择低基数分区键
重要的是,过多的部分将对查询性能产生负面影响。如果部分数量超过指定的总限制(在总数或每个分区),ClickHouse 将因此对插入作出响应,提示“部分太多” 错误。
选择正确的 基数 对于分区键至关重要。高基数的分区键——即不同分区值的数量较大——可能会导致数据部分的激增。由于 ClickHouse 不会合并跨分区的部分,过多的分区将导致未合并的部分过多,最终触发“部分太多”错误。合并是必要的 ,以减少存储碎片并优化查询速度,但对于高基数的分区,该合并潜力会丧失。
相反,低基数分区键——具有 100 到 1,000 个不同值——通常是最优的。它能够有效地进行部分合并,保持元数据开销低,并避免在存储中创建过多对象。此外,ClickHouse 自动在分区列上建立 MinMax 索引,这可以显著加快对这些列进行过滤的查询。例如,当表按 toStartOfMonth(date) 进行分区时,按月过滤可使引擎完全跳过无关的分区及其部分。
虽然分区可以在某些查询模式中提升性能,但它主要是一种数据管理特性。在许多情况下,由于数据碎片化增加和扫描更多部分,在所有分区间查询可能比使用非分区表更慢。明智地使用分区,并始终确保所选键是低基数并符合您的数据生命周期政策(例如,通过 TTL 进行保留)。如果您不确定分区是否必要,您可以先从不使用分区开始,根据观察到的访问模式再进行优化。
