ClickHouse Cloud クイックスタート
リストに 4 つのデータベースが表示され、その中に自分が追加したものも含まれているはずです。
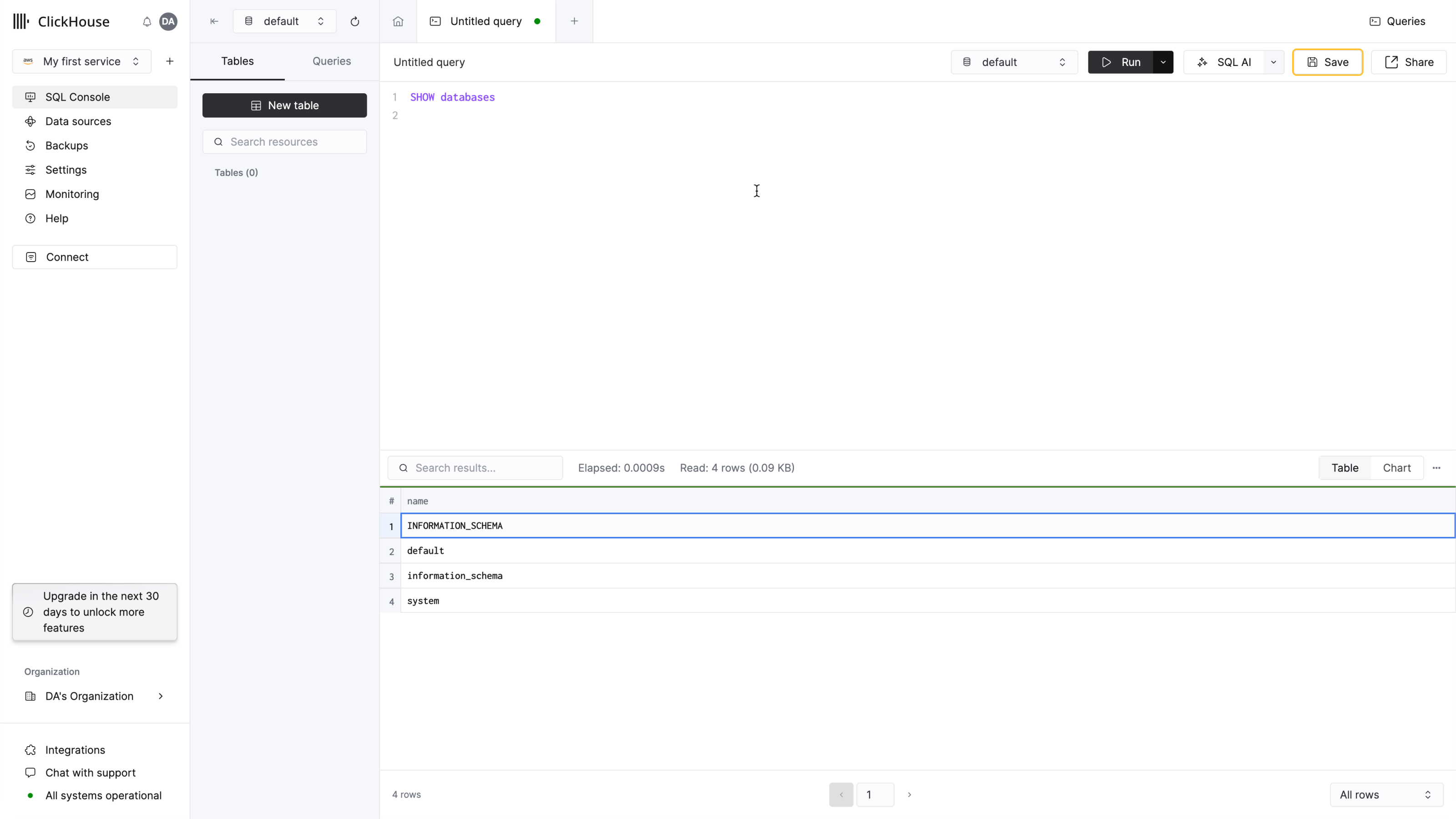
これで、新しい ClickHouse サービスの使用を開始できる準備が整いました!
アプリを使って接続
ナビゲーションメニューから接続ボタンを押します。モーダルが開き、サービスの資格情報を提供し、インターフェースまたは言語クライアントへの接続方法に関する一連の手順が表示されます。

言語クライアントが表示されない場合は、統合リストを確認してください。
データの追加
ClickHouse はデータと共により良くなります! データを追加する方法はいくつかあり、そのほとんどはナビゲーションメニューからアクセスできるデータソースページで利用可能です。

以下の方法でデータをアップロードできます:
- S3、Postgres、Kafka、GCS などのデータソースからデータを取得するための ClickPipe を設定する
- SQL コンソールを使用する
- ClickHouse クライアントを使用する
- ファイルをアップロードする - 受け入れられるフォーマットには JSON、CSV、TSV が含まれる
- ファイル URL からデータをアップロードする
ClickPipes
ClickPipes は、多様なソースからデータを取得する作業を簡単にするための管理された統合プラットフォームです。最も要求を満たすワークロードのために設計された ClickPipes の堅牢でスケーラブルなアーキテクチャは、一貫したパフォーマンスと信頼性を保証します。ClickPipes は長期ストリーミングニーズまたは一度きりのデータロードジョブに使用できます。

SQL コンソールを使用してデータを追加
ほとんどのデータベース管理システムと同様に、ClickHouse はテーブルを データベース に論理的にグループ化します。ClickHouse で新しいデータベースを作成するには CREATE DATABASE コマンドを使用します:
次のコマンドを実行して、helloworld データベース内に my_first_table という名前のテーブルを作成します:
上記の例では、my_first_table は 4 つのカラムを持つ MergeTree テーブルです:
user_id: 32 ビットの符号なし整数 (UInt32)message: String データ型で、他のデータベースシステムのVARCHAR、BLOB、CLOBなどのタイプを置き換えますtimestamp: DateTime 値で、時点を表しますmetric: 32 ビットの浮動小数点数 (Float32)
テーブルエンジンは以下を決定します:
- データがどのように、どこに保存されるか
- サポートされるクエリ
- データがレプリケーションされるかどうか
選択できるテーブルエンジンは多く存在しますが、単一ノードの ClickHouse サーバーでのシンプルなテーブルには MergeTree が適しているでしょう。
主キーの簡単な紹介
進む前に、ClickHouse における主キーの機能を理解することが重要です(主キーの実装は予想外のものに見えるかもしれません!):
- ClickHouse における主キーはテーブル内の各行に対して 一意ではない です
ClickHouse テーブルの主キーは、ディスクに書き込む際のデータの並び順を決定します。8192 行または 10MB のデータごとに(インデックスの粒度と呼ばれます)、主キーインデックスファイルにエントリが作成されます。この粒度の概念は、簡単にメモリ内に収まる スパースインデックス を作り、グラニュールは SELECT クエリの際に処理される最小のカラムデータのストライプを表します。
主キーは PRIMARY KEY パラメータを使用して定義できます。PRIMARY KEY が指定されていないテーブルを定義すると、キーは ORDER BY 句に指定されたタプルになります。PRIMARY KEY と ORDER BY の両方を指定すると、主キーはソート順のサブセットでなければなりません。
主キーはまた、(user_id, timestamp) のタプルであるソートキーでもあります。したがって、各カラムファイルに格納されるデータは user_id で、次に timestamp でソートされます。
ClickHouse のコア概念について詳しくは、"Core Concepts" を参照してください。
テーブルへのデータの挿入
ClickHouse ではおなじみの INSERT INTO TABLE コマンドを使用できますが、MergeTree テーブルへの各挿入により、ストレージ内に パーツ が作成されることを理解することが重要です。
バッチごとに大量の行を挿入します - 数万行または数百万行を一度に挿入してください。心配しないでください - ClickHouse はそのようなボリュームを簡単に処理できます - そして、サービスへの書き込みリクエストを減らすことで コストを節約 できます。
シンプルな例でも、同時に 1 行以上を挿入しましょう:
timestamp カラムはさまざまな Date と DateTime 関数を使用して生成されることに注意してください。ClickHouse には役立つ関数が数百ありますので、Functionsセクション で確認できます。
正常に動作したことを確認しましょう:
ClickHouse クライアントを使用してデータを追加
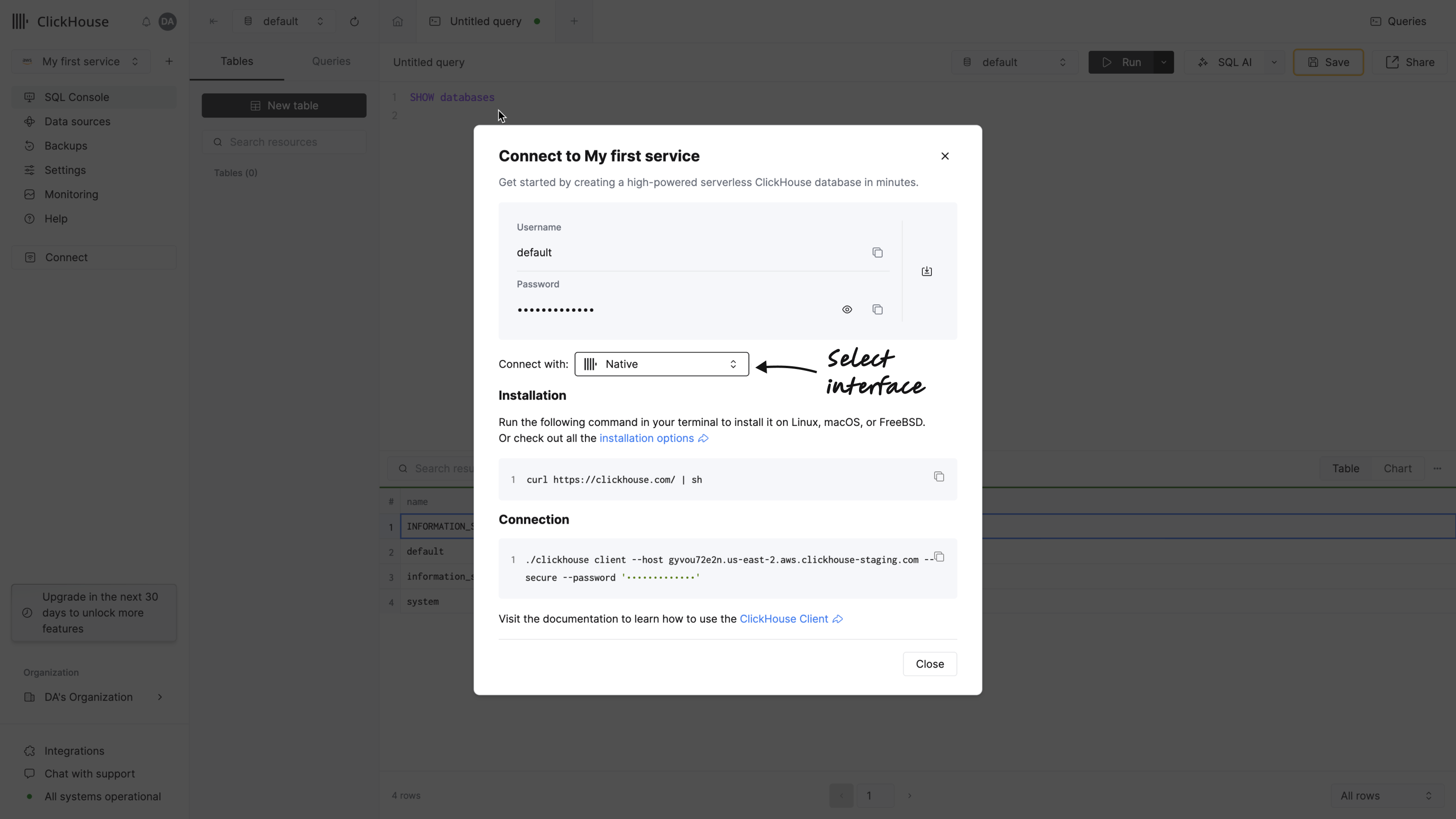
コマンドラインツール clickhouse client を使用して、ClickHouse Cloud サービスに接続することもできます。左のメニューから Connect をクリックしてこれらの詳細にアクセスします。ダイアログからドロップダウンリストで Native を選択します:
-
ClickHouse をインストールします。
-
次のコマンドを実行し、ホスト名、ユーザー名、およびパスワードを置き換えます:
スマイルマークのプロンプトが表示されたら、クエリを実行する準備が整ったことを示しています!
- 次のクエリを実行して試してみてください:
応答がきれいなテーブル形式で返されることに注意してください:
FORMAT句を追加して、ClickHouse の 多くのサポートされた出力フォーマット の 1 つを指定します:
上記のクエリでは、出力がタブ区切りで返されます:
clickhouse clientを終了するには、exit コマンドを入力します:
ファイルをアップロード
データベースを始める際によくあるタスクは、既にファイルにあるデータを挿入することです。クリックストリームデータを表すサンプルデータがオンラインにあります - それにはユーザー ID、訪問した URL、イベントのタイムスタンプが含まれます。
data.csv という CSV ファイルに以下のテキストが含まれているとします:
- 次のコマンドが
my_first_tableにデータを挿入します:
- SQL コンソールからクエリを実行すると新しい行がテーブルに表示されることに注意してください:

次は何をしますか?
- チュートリアルでは、テーブルに 200 万行を挿入し、いくつかの分析クエリを書きます。
- 挿入方法に関する指示がある サンプルデータセット のリストがあります。
- ClickHouse の使い始め方 に関する 25 分のビデオをチェックしてください。
- 外部ソースからデータが来ている場合、メッセージキュー、データベース、パイプラインなどへの接続に関する 統合ガイドのコレクション を確認してください。
- UI/BI 可視化ツールを使用している場合は、ClickHouse への UI 接続に関する ユーザーガイド を参照してください。
- 主キー に関するユーザーガイドは、主キーおよびその定義方法について知っておくべきすべてのことです。
